vScope’s automatic inventory runs without the use of any agents. The default discovery settings are set to run once a day and are configured to the size of a datacenter of up to 400-500 units. If you want to increase the discovery scope of vScope (eg. add discovery of large client networks) you might want to make sure to optimize the discovery time by changing some settings in the vScope platform.
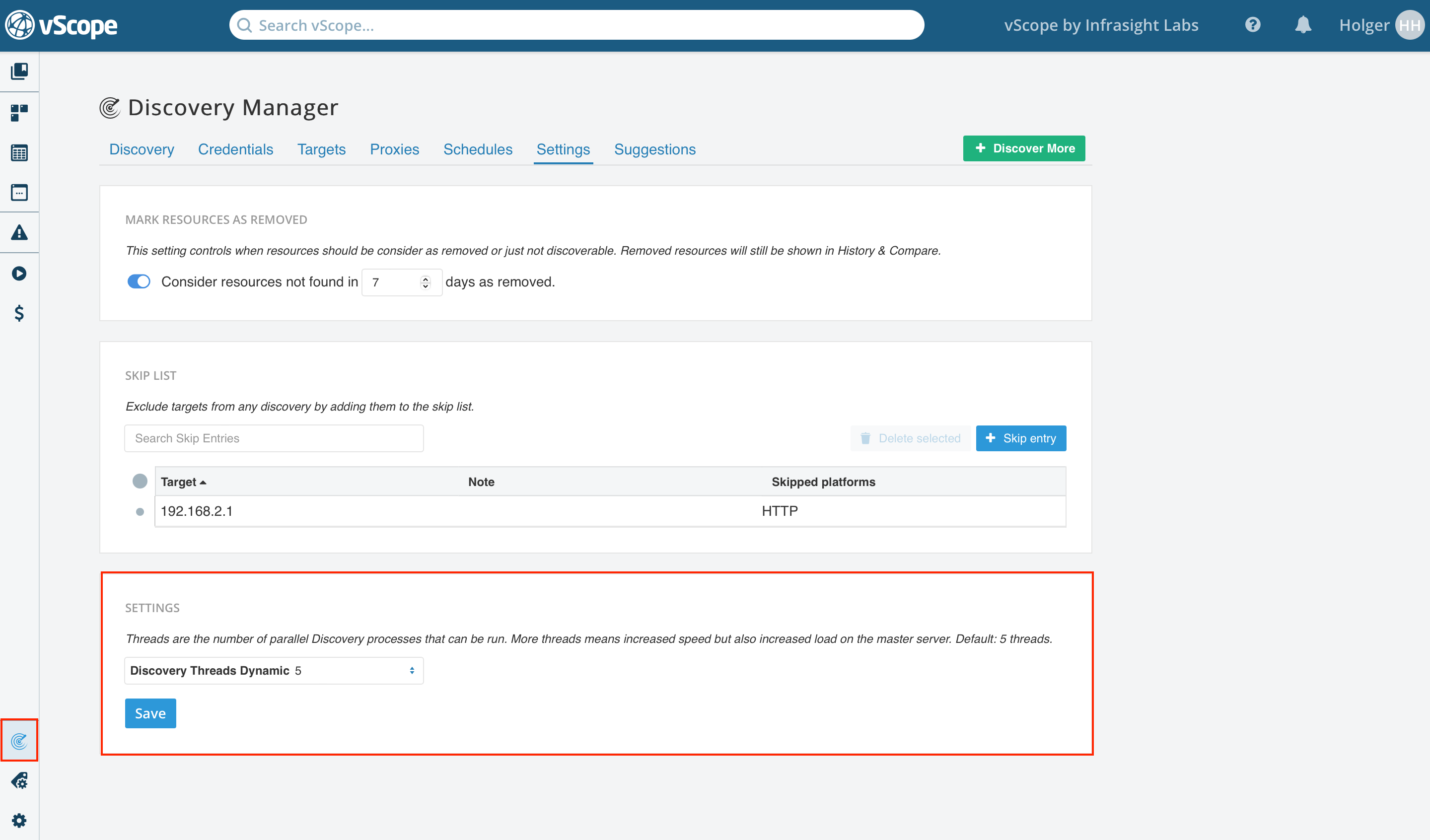
1. Increase the number of parallell discovery threads
By increasing the number of discovery threads, vScope will be able to inventory more resources simultaneously. The default number of parallell threads is five. Increasing this number is an easy way to speed up the discovery but remember that this will also require more RAM to be provisioned to vScope and the vScope server.
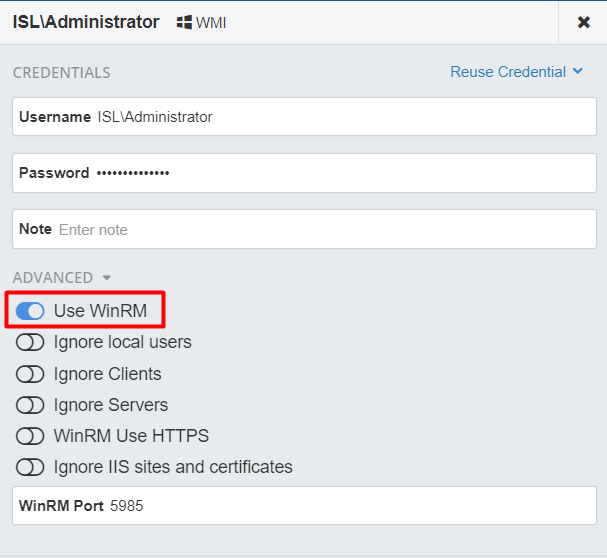
2. Use WinRM instead of WMI for OS inventory
WinRM could be described as WMI 2.0 and is the fastest version to inventory Windows operating systems. It is perfect for discoveries of large client networks or remote branches where latency may occur.
Read more
3. Changing hardware configurations
An easy way to save discovery time is to use SSD storage for the vScope server. This optimizes the I/O from vScope and will allow a faster discovery. Also, increasing the RAM configuration of the server will ease the load of the discovery.
Read more
4. Setup discovery proxies
By using proxies, the discovery load can be distributed to multiple discovery engines. This is not only relevant for closed nets or remote branches but also a way to ease the load from the main vScope.
Read more
5. Ensure streamlined credential/target setup
Have a look in the discovery Manager and overview what credentials are being used to scan the targets. Can the number be reduced? Are you using multiple credentials on large IP ranges? Is any account obsolete? Just some minor tweaking can have major impact on the total discovery time.
Also, please check if you have added too many and too large ranges. Notice that /16 ranges for instance, includes 65 536 IPs. If it is possible to tighten these ranges by dividing it up into several smaller ranges, excluding those where no data is to be found.